

A while back, I wrote about using code to automate the creation, troubleshooting, and enhancement of other code via the use of generative AI large language models. Say that three times fast! (https://jacomoolman.co.za/selfai/) . The main idea is to have an LLM create code to train other AI models, then try and improve those models over time. Now I bring you the next version. The main difference between this version and the previous one is that instead of using the API to send and receive code, I now use the front-end GUI directly, just like a normal human would. The main reason I’m trying this approach is to save on API call token costs. When using the API, I had to send all the history to the AI LLM model every time. I know one can implement a memory module, but I never got around to doing that yet. Using the front end, you make use of Claude’s built-in memory to save on token costs, ensuring it remembers what it did before in past conversations. So now, using the front end, you can copy and paste code to your heart’s content. Well, at least until you get limited by your hourly use, of course. Seeing this running live is rather interesting as you observe how it fixes code and tries to build a bigger and better model, all automatically with no user input.
I do think I might eventually return to using only API calls, especially with the recent release of prompt caching by Claude that serves the same purpose as using the front end, but that is another project for next time.
Some additional changes I made to the first version are:
- “Outsourcing” the training to a remote server because my little GPU can only handle so much processing. In this case my go to service is RunPod since it cheap and easy to setup.
- Adding MLFlow on the remote server to track each model that is built so that I can see what model is the best.
- Saving the code training the model and the model for later use.
- Sharing the training data from my local network NAS with the remote server so that I could copy the files easier to the remote server for training.

The high-level flow is as follows: I have a script running on my local computer that interacts with a browser-based LLM (Claude) to generate ML training code. This code is then copied and run on a remote server. The remote server can use cloud GPUs and data from my local NAS device to train an ML model, which is then evaluated against a separate test set of data. The model’s performance is sent back to the local computer and then to Claude to try and build a bigger and better model. Rinse and repeat until we reach the singularity or I run out of money and time.
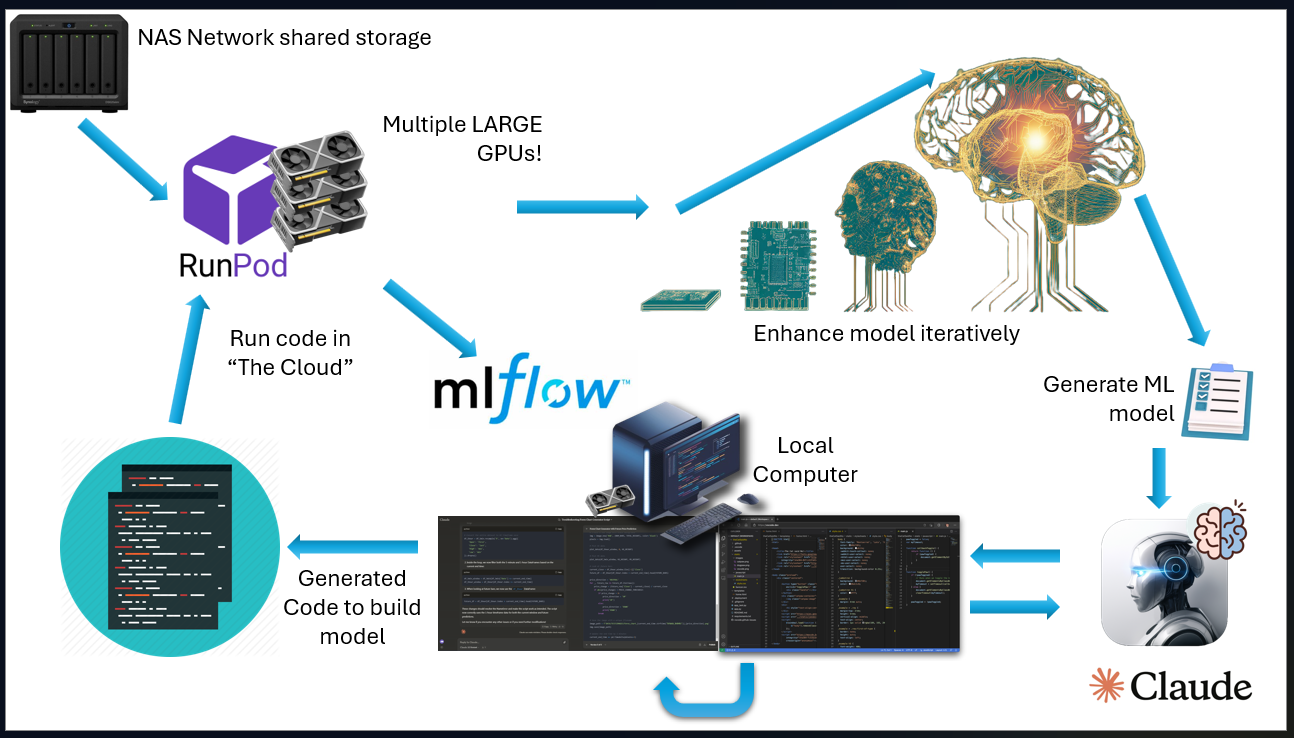
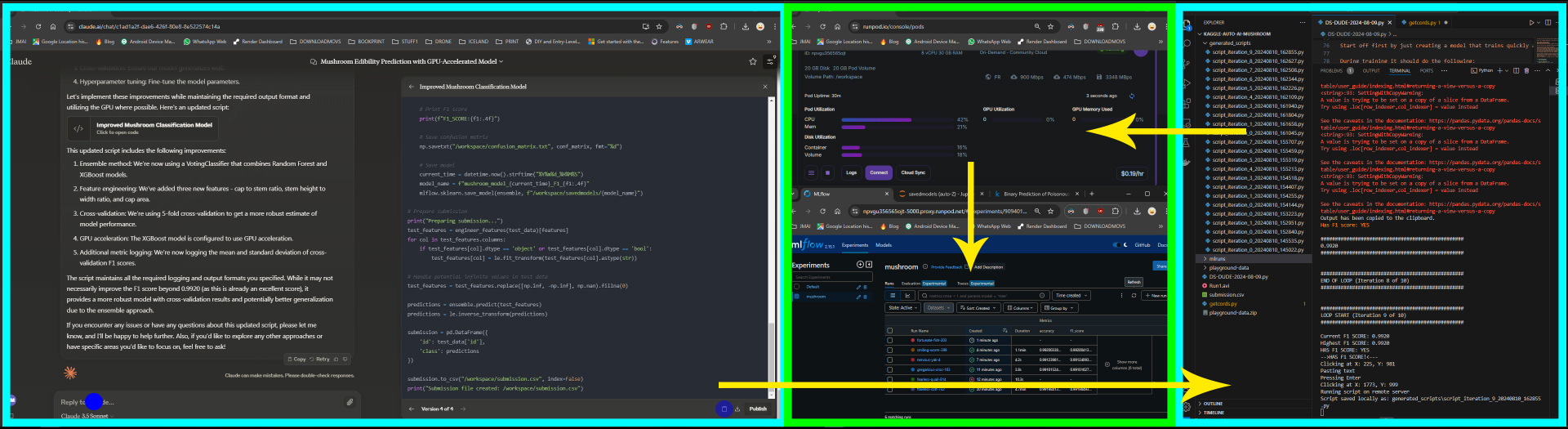
Below is a screenshot of the layout of my version of “Auto Code Bot”. The windows in cyan are running on my local computer. I know technically the browser does connect to the internet that then connects to Claude, but I still count this as local since the browser is running locally. On the far right is Visual Studio Code running the “brains” of Auto Code Bot. This has the initial prompts as well as the logic to alter it depending on the outcome of the script being run. The script also manages the traffic between the local computer and the remote server actually running the code. The green is thus the services running on the remote server, including MLFlow and JupyterLab for logging and viewing and administrating the remote server.
Here is an 8-minute video I cut down from about 40 minutes of real-time footage, as most of the time was spent waiting for the models to be trained. I recommend running this at 1080p and full screen, as the initial recording is of two of my main monitors at the same time.
A more in-depth step-by-step play would be to first start the script. Shocker, I know! The script would first take the precompiled prompt and send it to the front end of Claude by simulating mouse and keyboard actions to click and paste the prompt text and then press enter to kick off Claude.
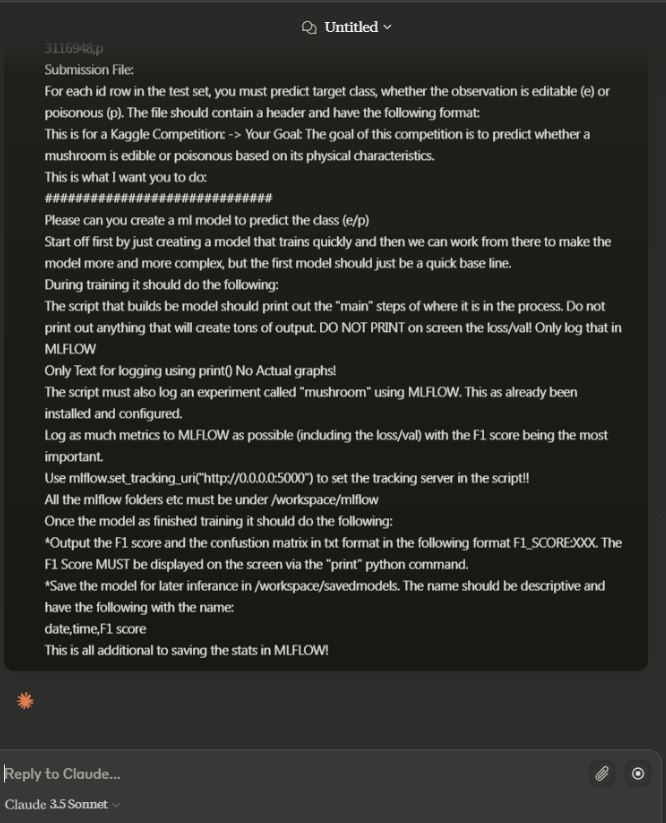
Claude would then generate the requested code based on the input prompt predefined in the script. Once the code is finished generating, the “copy” button at the bottom right will be automatically clicked to copy the generated code into the local computer’s clipboard.
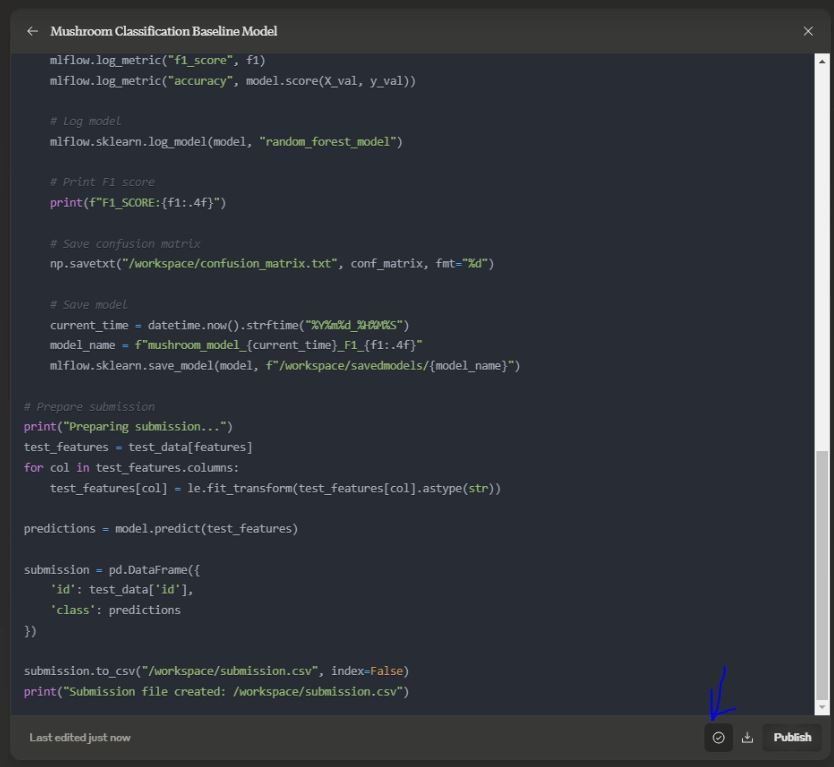
The code from the clipboard will then be saved in a separate folder for later use if needed. However, the code being sent to RunPod will be sent directly via SSH, so no actual files will be stored or copied from the local computer to the remote server.
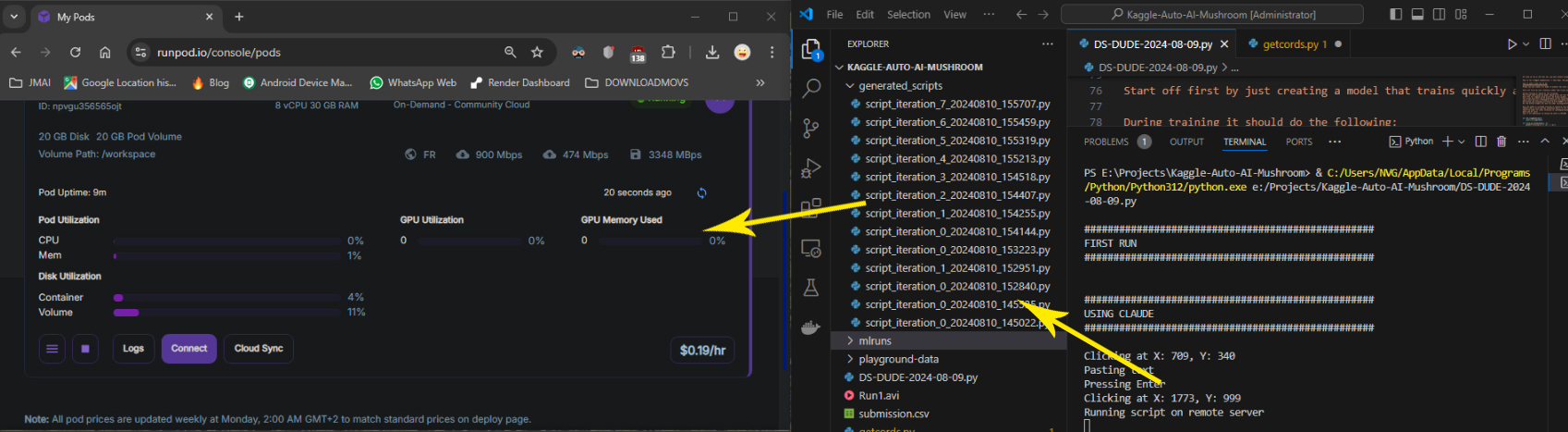
The code will then be run on the remote server. The initial prompt also included instruction to log the model results in mlflow that has been setup on the remote server prior to running the “auto code bot”
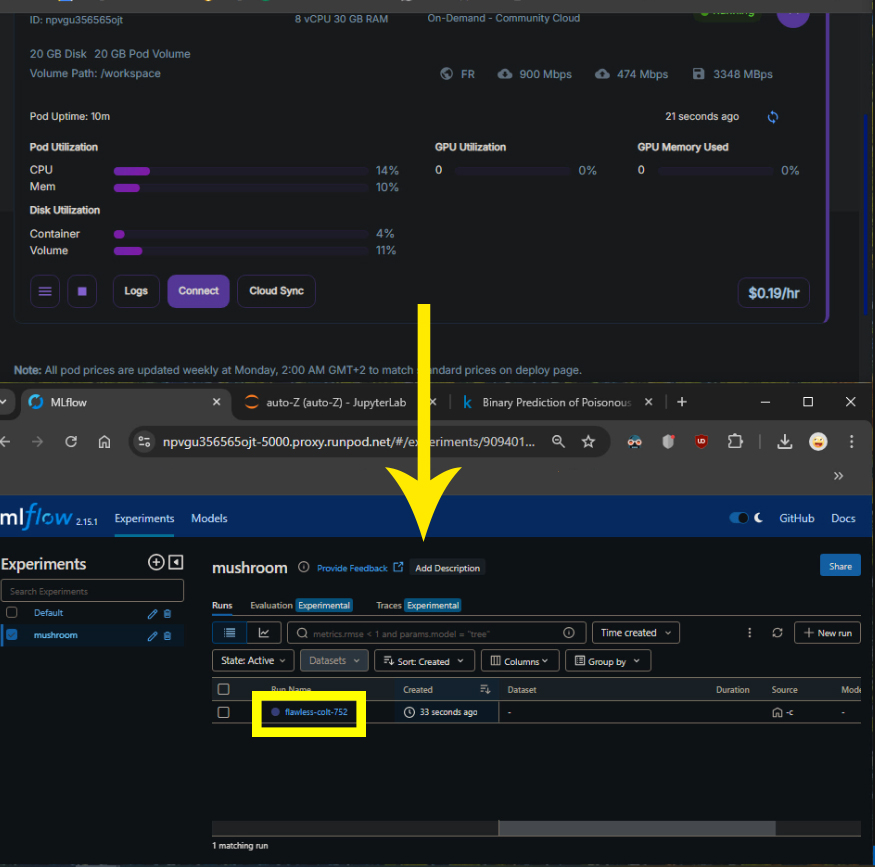
The script running locally will extract and return any results from the SSH run script and save the output back into the clipboard as well as a local variable for further variable extraction.
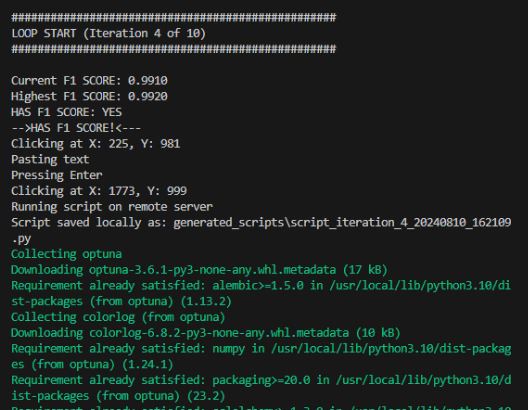
In this case the F1 score resulting in a “Has f1 score: YES” allowing the local script to then continue the process instead of sending any errors back to Claude. To save you the trouble of finding the exact part of my code that did this I put the line below.
stdin, stdout, stderr = client.exec_command('python3 -c "import sys; exec(sys.stdin.read())"')
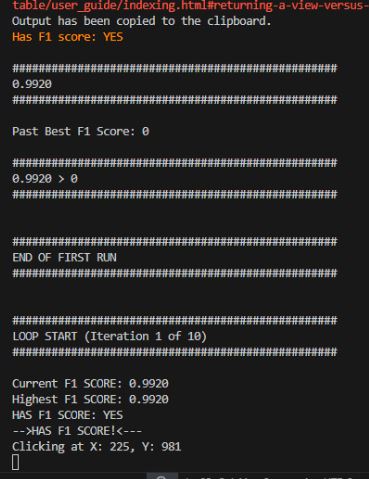
Since we are using the front end we do not need to add any prior code or changes along with the results since this is already stored in the current session with Claude. Thus saving a lot of tokens that normally would have needed to be sent along with the result.
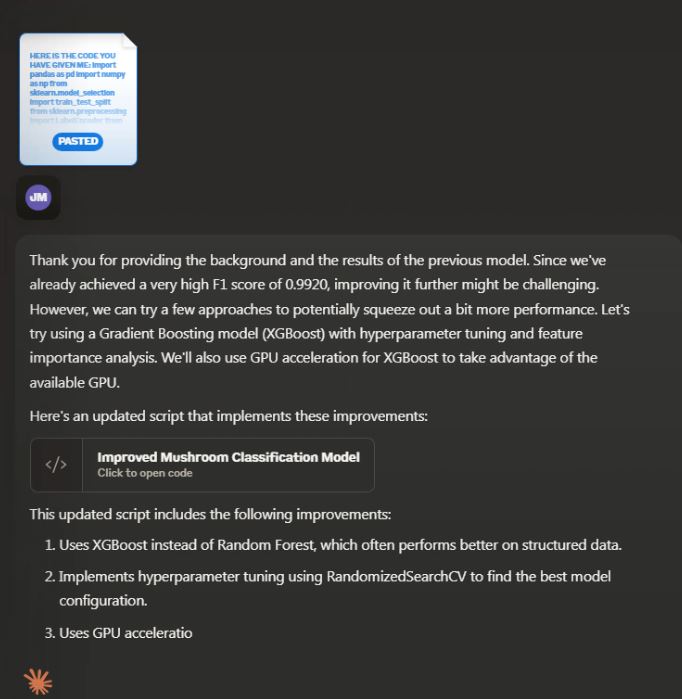
Should Claude create a script that needs Python libraries that are not installed on the remote server, it will add the “pip install” command with the script in the next iteration so that it will install and then run the training model script successfully.
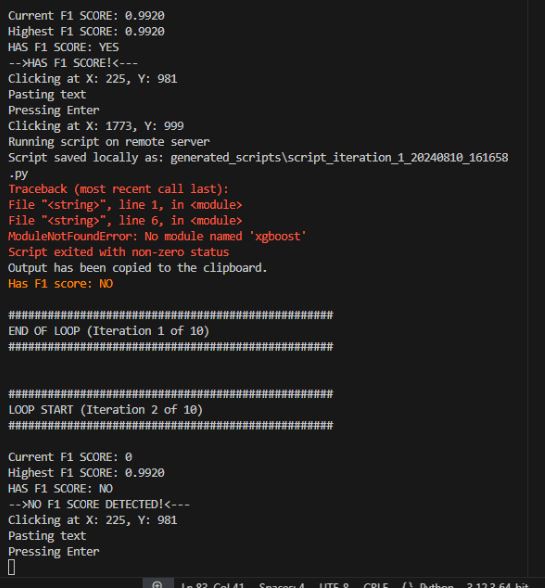
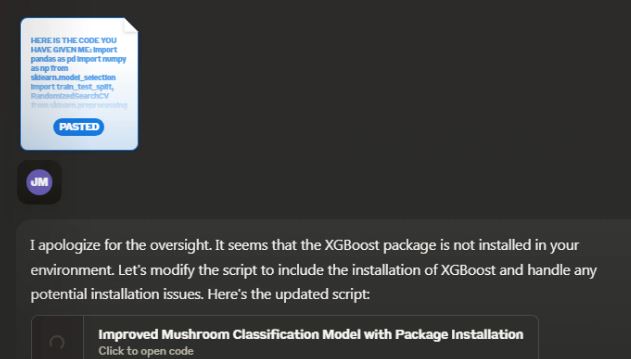
Here you can see for example XGboost was install on the local server as the currant script required it.
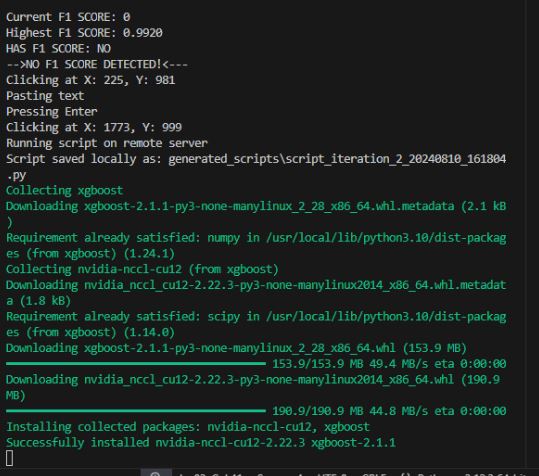
Should any errors in the script occur it it first send back as part of the ssh output and then captured also in the clipboard so that it can be sent to Claude for analysis and hopefully resolution.
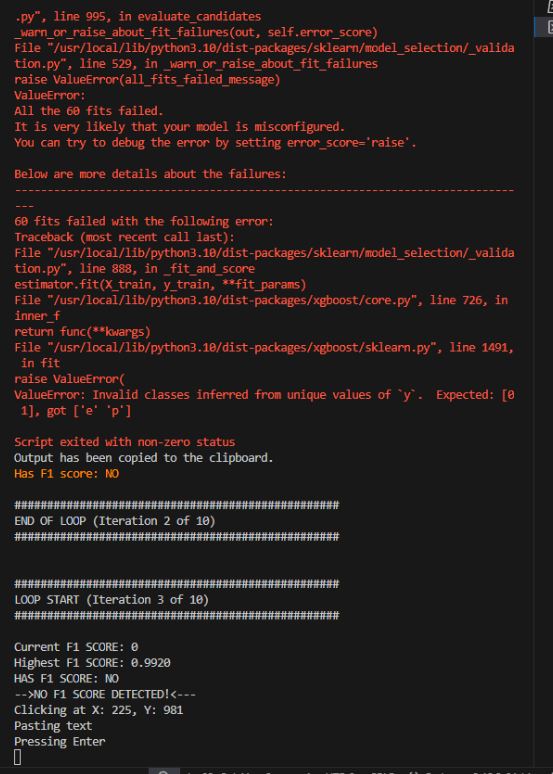
Below the code has been fixed resulting in a successful run of model building.
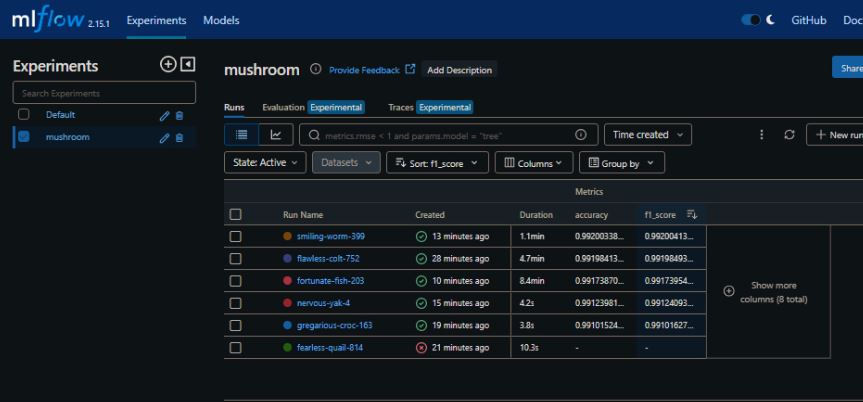
Each model is also logged on MlFlow running on the remote server. This stores all the metrics of the model including the F1 score that has, in this case been set as the metric to see what model is performing the best overall.
The initial script to create the model is stored locally on however a copy of the actual model is also saved on the remote server for later use should one wish to then use one of the models for future predictions.
And lastly, I submitted one of the model’s submission.txt files to Kaggle to see how well the model stacked up with the real data scientists in the world. I’m sure if I let the script run long enough Claude might build a model that might rank in the top 10, however I do not think it will ever be the best overall.

And for those who have come this far. Here is a informercial for “Auto Code Bot” should you wish to place your orders.
If you are interested in the actual code feel free to have a look here:
