

I was having a talk with my manager a while back during a conference we attended together. The topic came up if would be possible to give a LLM (Large Language Model) your data and then and have it learn more about you. Then if someone wants to know more about you they can simply ask the model trained on your data.
Well in the world we find ourselves in, where the technology changes on almost a daily basis, I thought I would see if I can not make this idea an reality. Also as a side note, when I started this project where where no services to facilitate this, however now I see a few a sprung up.
Thus I decided to create a proof of concept. Where I give the model all my details and then see how much it could learn about me.
As I did not want to use any third party tools I decided to use one of openAI’s models and use fine-tuning (the process of adapting a pre-trained model to a specific task by further training it on a smaller, task-specific dataset) to create my own custom model. Unfortunately going about it like this one can not simply just import text and tell it to build you a model based on your text. It needs to be in a specific format.
According to the documentation OpenAi provided your input text needs to be in a format similar to this: {“prompt”: “<prompt text>”, “completion”: “<ideal generated text>”} This would mean every training question and answer would need to be in this format else you would not be able to use it to train your model on.
So I spend hours writing out prompts right? If only where was a way one could somehow automate it. You know in the modern age of AI and all… Oh wait, yes you can. I gave GPT raw copy pastas of my CV, a personality test I took part in, some mock interview questions and even some random facts about myself. Then simply told it to come up with prompts using the correct format.

I even asked it to pretend to be someone interviewing me and ask me a lot of questions. I then answered those questions and then fed it back to GPT to build the prompts for me.
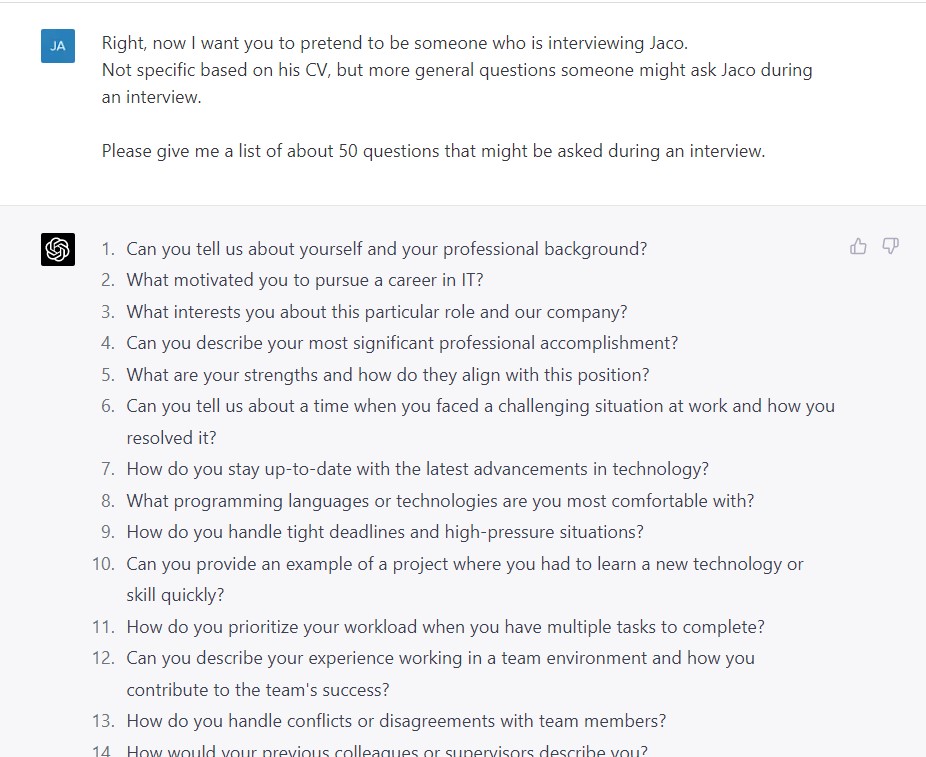
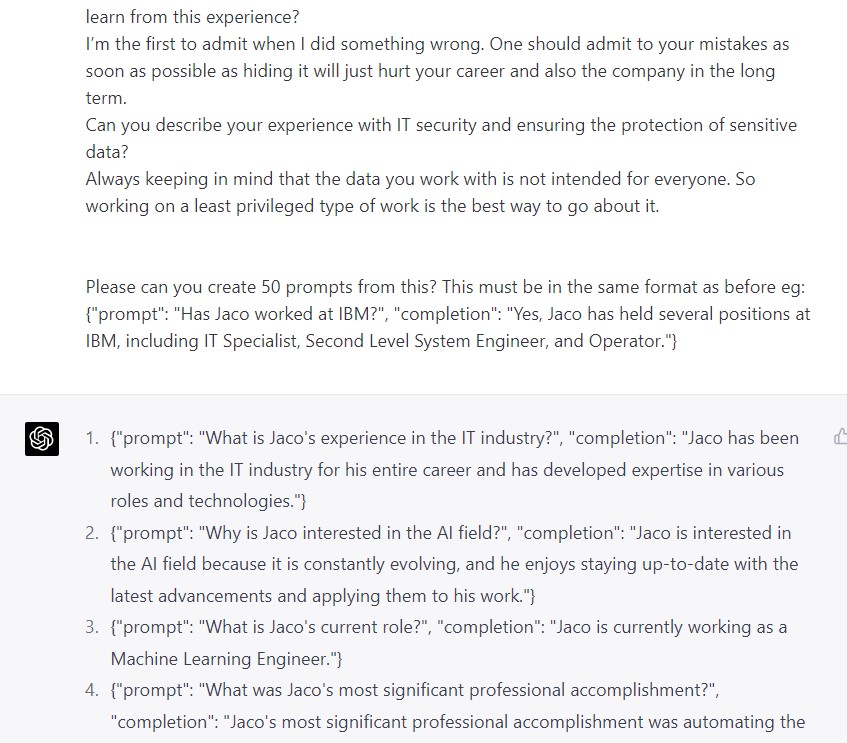
Doing so GPT managed to create about 1000 prompts for me.

And now on to the fun stuff. Part of OpenAI’s CLI there is a tool you can use to check all your prompts to make 100% sure it’s in the right format. This is essential I tried to skip this step and the training failed after about 30 minutes or so, and still got charged for the training time.
Then once I have my correct final formatted input data it was time to start the training (..again) I decided to the davinci model. Even though it was the most costly model I decided to use it as I wanted to try and get the best results. I decided to leave all the settings on default, however in hindsight I might have increased the number of epochs (the count of complete passes through the training dataset during the model’s training process) a bit more.
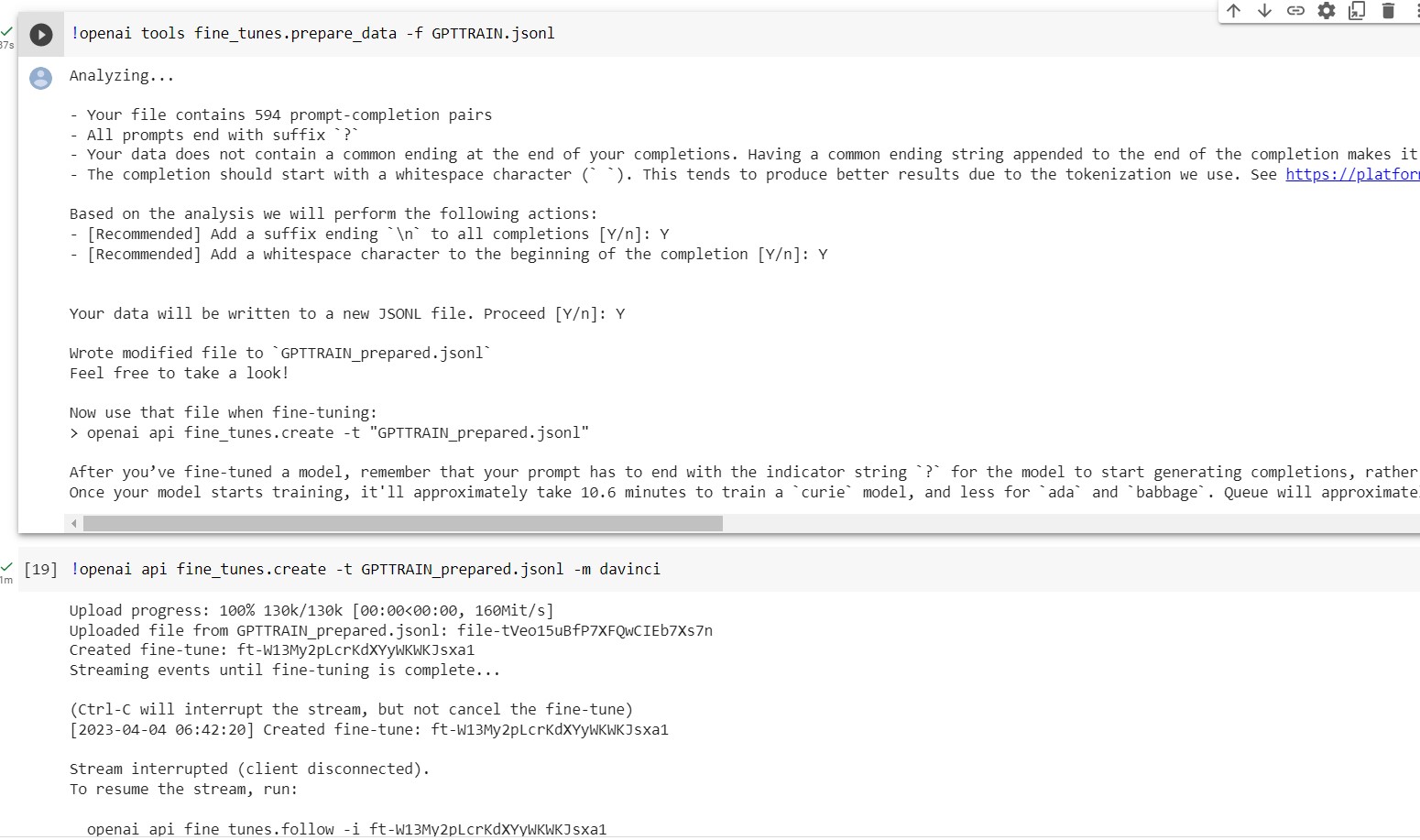
It seems there where a lot of other people also trying to train their custom models as the queue to even start training your model was rather long. It took about an hour to get to number 0 in the queue.
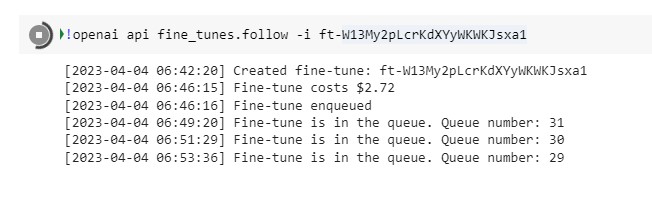
When the model was finally finished training I was rather eager to find out how much it actually knew about me and if one can in fact use this to substitute yourself during an interview. I played around with the temperature (how creative the model is when answering your questions) and the number of tokens per answer (how much text is it allowed to use in it’s response). I also needed to add a “end prompt” else the model would just keeping on asking it’s own questions and answering them instead of waiting for me to ask new ones. Basically something for the model to know when to stop predicting more text. In this case it was just the newline (‘\n’)
Below is some examples I ran straight from the notebook I used to train the model:



I did not know Windows or Unix was a programming language? haha

Well how did it do? Well lets just say I’m not going to make this live and put it on my website for possible employers to interview the virtual me. When I asked it something that was not part of the dataset it would just make up some random facts. Even if I asked it something that was trained on it would sometimes just add additional facts that was not true. Even asking what my cell phone number was, something that was part of my CV, it sometime just made up a random number for my contact information. So using this “virtual me” to represent myself might be a bad idea if I ever want a new position.
I’m sure if I added more training prompts, and also added some negative prompts like “Jaco does NOT have a dog” and “Jaco can NOT play the piano” it might be more accurate. However this was more a proof of concept to see if this would actually be possible at all.
To have at least something to show I decided to create a mockup of what my virtual me chat bot would have looked liked. If I was confident enough it would not try and tell people I’m the Pope and know what the question to 42 is. So good idea and well worth revisiting sometime in the near future.
