

Ever wondered what would happen if you told an AI to build a smarter AI? Then take that smarter AI and tell it to build an even smarter AI? Scary and intriguing at the same time, I think. While enjoying a wonderful time sitting in traffic, I found myself thinking just that and wondered if I might be able to pull something like that off. Well, Skynet has not been created, and you are still reading this, so it’s safe to say that I haven’t fully accomplished the exact idea of an ever self-improving AI. I did, however, manage to create the next best thing: using AI to build another AI model to accomplish a specific task, and then improve the AI to get better and better results.
We have all been there. Asking GPT or some similar LLM to help you write a basic function only to get an error when you run the code. Then having to tell the LLM the error to help you fix the code. Rinse and repeat over and over until you hopefully get working code or, even better, get code that actually does what you want it to do. All of this takes time: copying, pasting, waiting for a response, running the code, getting a new error, and so on! Well, what if you could just take out the middle person, namely you, and let the LLM just fix its own code? Or even better, make its own code better with every iteration.
Instead of using prebuilt agent frameworks like CrewAI, AutoGEN, or even Devin, I wanted to build everything from scratch to have the most control over the whole process. I did not use “agents” per se, more like a thorough process of coding and prompting in a VS Code window, pressing “MIX,” and seeing what comes out.
I did not set my initial sights too high, and for the first attempt, I only wanted the LLM to fix its own code by building a basic AI model to train and test one of the common Kaggle competitions. In this case, the Space Titanic competition, since the old Titanic one has been done so many times.
Since I knew I was going to run this script more than once (millions of times), I first opted to use LLAMA 3 using GROQ’s API. Not only is it the fastest LLM API out there, it is free! At least at the time of me writing this.
I started by compiling the initial prompt, telling the LLM what I wanted to do, where the files were, and what outcome I was expecting. In this case, I wanted the generated script to return an F1 score. I split the “main” prompt into sections, namely a “requirement” section followed by an “outcome” and an “instructions” section. Sure, I could have just created one big prompt, but this way, I could use sections of the prompt in my code further down without having to rewrite sections of it. I told the LLM I wanted the output to be in a specific format so that I could then extract sections of it as I saw fit. I wanted a section where it gave some sort of reasoning as to why it’s doing what it’s doing. This was not only good to know why the LLM is doing what it’s doing, but also to help the internal reasoning of the LLM and give it a little bit of a push to get the code right and not just spit out the first thing that comes to its “mind”.
Next, I told the LLM to return the actual code that will be run within “XXX” brackets. This way, I was able to extract the actual code out of the response while still being able to get additional information on top of the code being produced. Yes, “XXX” could have been anything, but I chose this as it was, at least according to me, the least probable text to also be produced anywhere else in the returning output.
After giving the LLM the initial instructions and hopefully getting code in the right format, I extracted the code and then executed it. Obviously, all code ever produced by an LLM has NEVER not worked the first time, right! So to resolve this, I added another step. After running the code, I captured the output of the produced code and gave it back to the LLM, asking if the output resembled that of the “outcome” I initially wanted. Having the initial prompt in sections, I was able to play Lego and simply reuse the “outcome” section again in the combined prompt, asking if what the script has produced is what I wanted. In this case, I wanted the script to output “F1:<score>”. I told the LLM to return “CORRECT” or “WRONG” depending on if the script returned an “F1” score or not.
Very surprisingly, sometimes the LLM returned a “WRONG” even when the script gave an “F1:<score>” output. It really was beneficial to also ask the LLM to add a reason and suggestions to fix the problem or error. By adding the output and the generated code, the LLM was sometimes able to see that even though the text “F1 score:” was being printed, the number next to it was NOT the F1 score, but something else. It seems the LLM was not only checking the outcome but doing code review as well at the same time.
Extracting the “CORRECT” or “WRONG” from the LLM output, I then used this to either go “NICE” and end the loop or feed the “broken” code, the output, and the suggested fix back to the LLM to try and rectify its code. I also had to add the outcome and instructions every time since there is no memory when calling an LLM via the API, and I did not want to spend more time building a memory module as well.
For the first attempt, I initially had all my code in one big Python script, but this became rather unmanageable very quickly, and I moved some of the basic functions to a separate module. Functions like calling the LLM and returning an output, for example. Functions that were either taking up space or that I needed to call more than once.
I must say I did not expect the “first” try to work so well. Sure, there were a couple of syntax errors, but the logic worked the first time!
Below is a screen recording of the first try. Keep in mind this was just to try and get the AI to fix its own code and resolve errors with no intervention from me. On the left are the “logs” containing the prompts and other output. On the right is the code being generated and updated by the LLM. You will see at the end there is a green “Success” along with the F1 score being displayed.
So after this, I set my sights on getting the LLM to build a better model with each iteration—not only to fix the broken code until it got a working script. This was slightly harder, and I had to do a lot more code/prompt mixing to get this working.
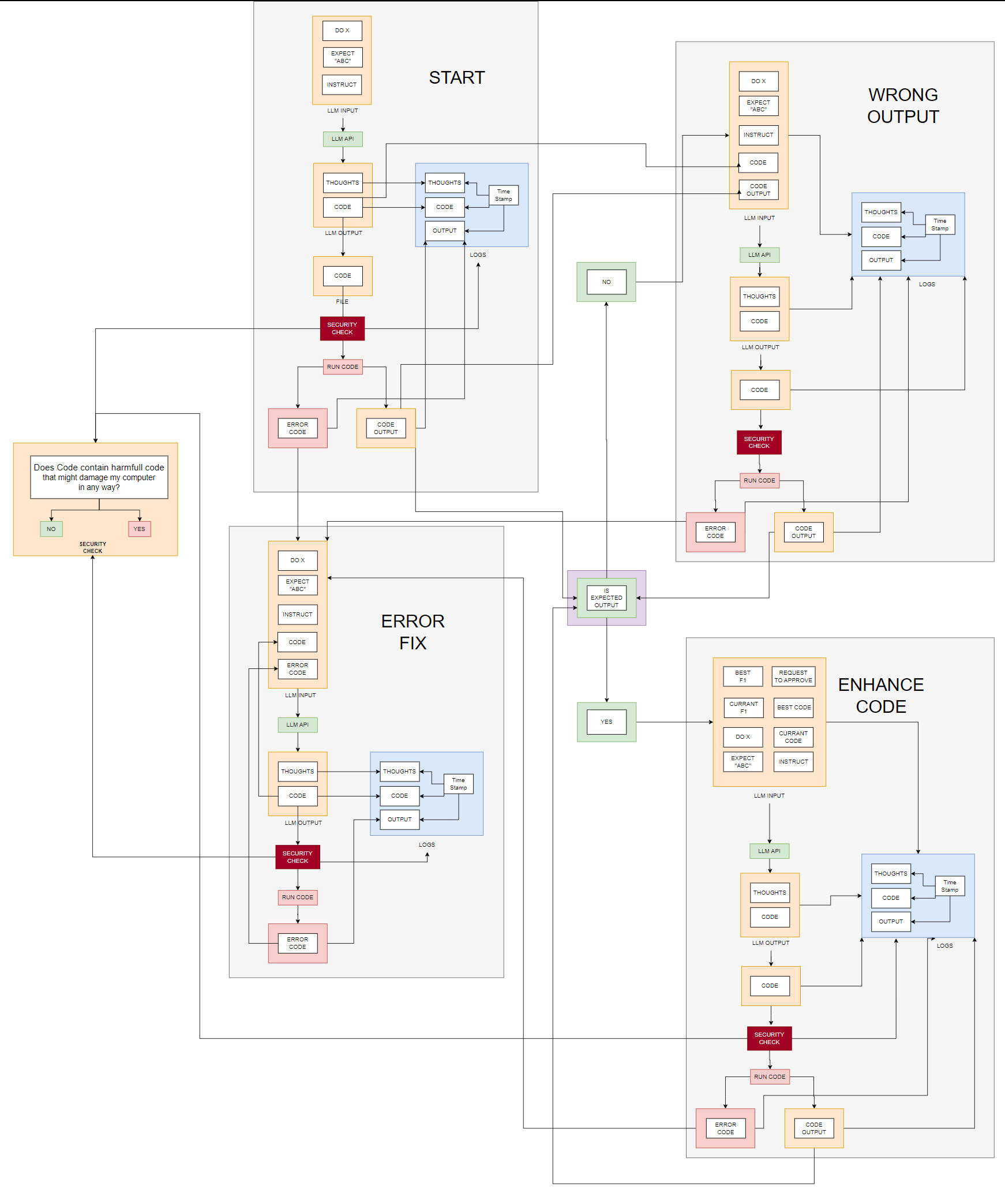
Above is the final diagram I came up with to accomplish this. Feel free to click on the diagram to get a better view. Here is a short description of what is going on. I had to have an initial output from some generated code, so the first step was very similar to the approach above. Adding what I wanted it to do, expect, and the instructions in the prompt, I got the first code back, working or not. I also ended up adding another “agent” in the mix to check the code before running it on my local computer, just in case the LLM deemed it necessary to delete my win32 folder because it wanted to speed up the training time of the generated model. You never know. I also wrote everything to a log, one for each time I had to start from scratch, mostly for troubleshooting, as there was a lot of text on the screen and it was hard to spot an issue by just looking at the raw output.
Once I got the output from the first run, the code simply checked if the output was what was expected or not, be it an error or some incorrectly formatted output. If there was an error, I would again send the error back along with all the previous instructions and the broken code, telling the LLM to try and fix whatever was broken.
The “fun” part came when the generated model actually produced a valid F1 score. This was the largest prompt, as I then gave the LLM the following:
- The current F1 score
- The best overall F1 score
- The current code
- The code that produced the best overall F1 score
- The default sections of expectations and instructions
- A final request to try and improve upon the code to get an even better F1 score.
In each step, the code was again checked for “security,” and all output was written to a file for later use or troubleshooting. Once this was all set up, I simply let it run and sat back with popcorn while watching the action. It was kind of insane watching one AI build another AI and then systematically improve the AI over and over, with reasoning and fixing bugs and errors.
My first design was just to get the LLM to build a model that worked. However, with the additional steps, the code got really long and complex. I ended up moving all the input prompts into a separate module where I could call each section by referring to its variable alone. I also moved a lot of functions to a separate module so that I could have a “one-screen” overview of the whole main process to make sure all is as it should be.
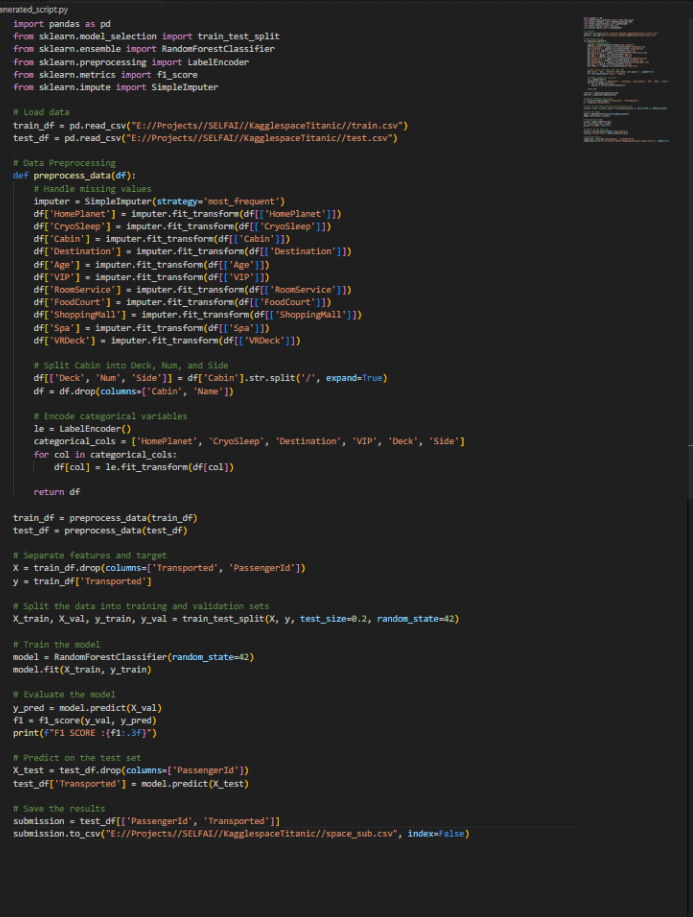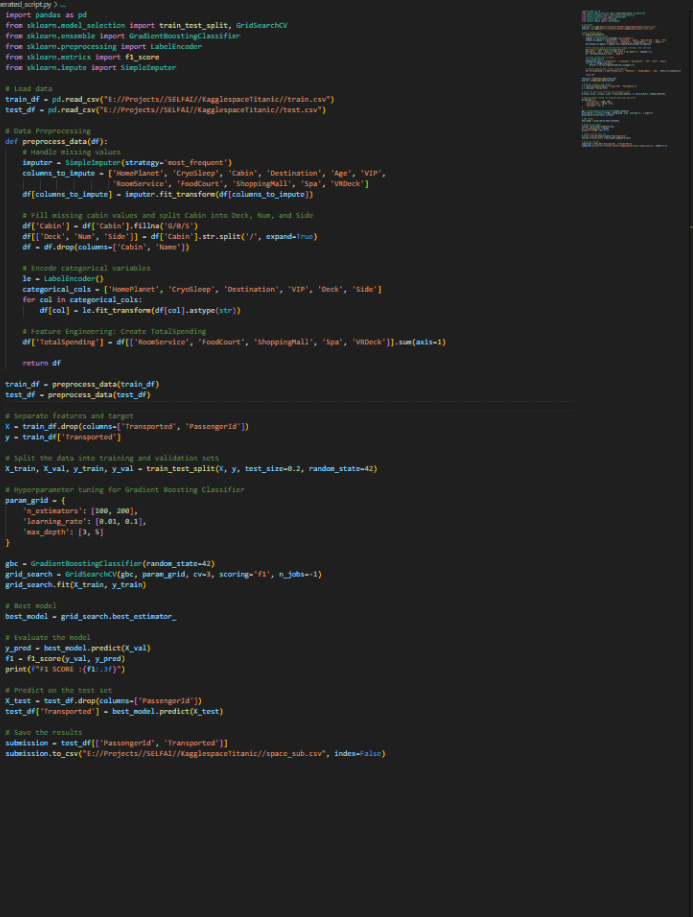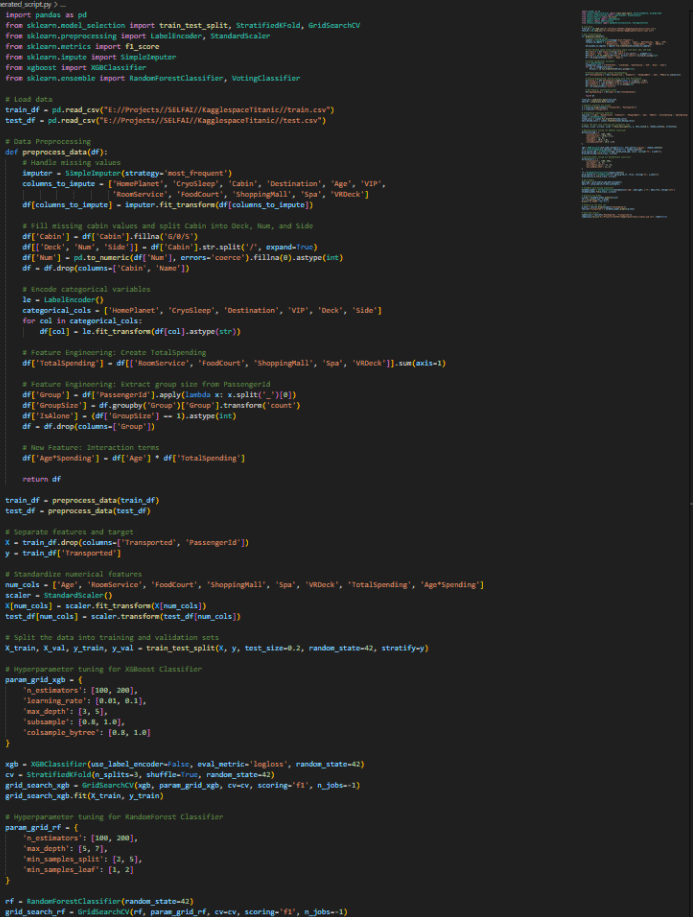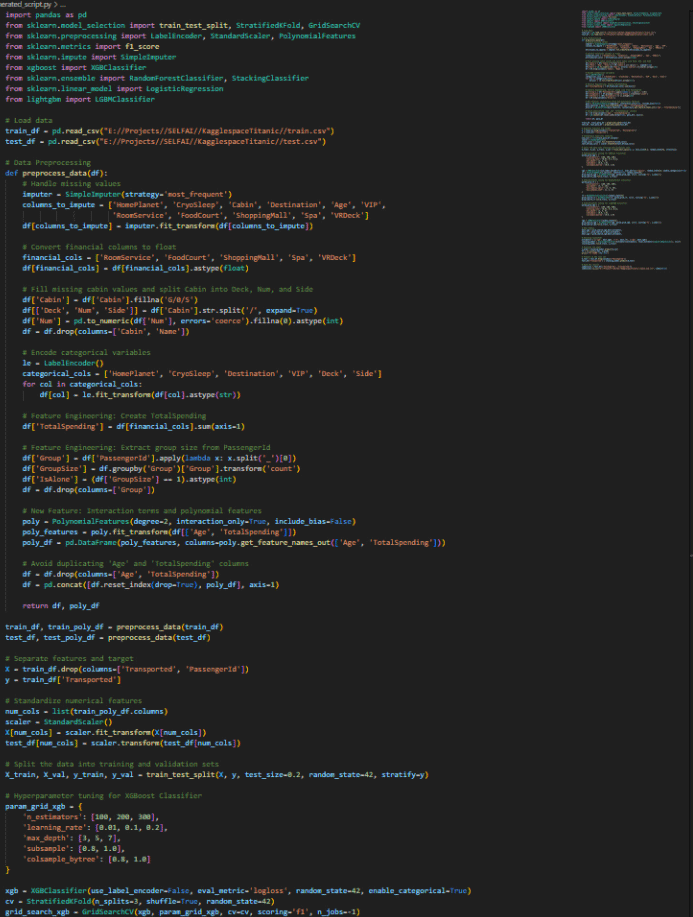
Below are a couple of screenshots of the generated model producing better and better F1 scores.

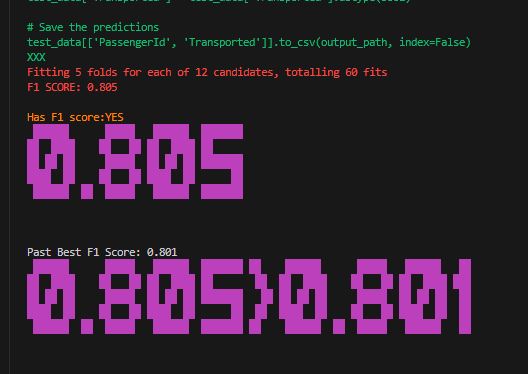
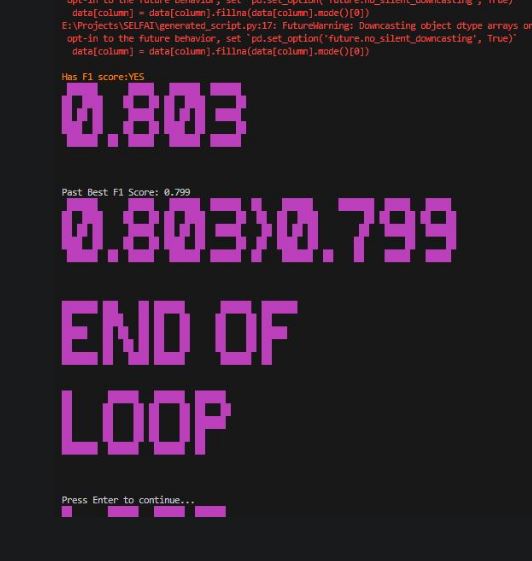
As mentioned above, my first try was using LLAMA 3. The model is really not too bad for an open-source model, but it cannot hold a candle to the top commercial LLMs out there. I opted to spend a couple of dollars to test out my setup with GPT-Turbo. Well, it was more than a couple of dollars. Because of the large amount of input and output tokens, each “run” cost me about $1 or more. I think the most was about $3. However, GPT-4 spent a LOT less time troubleshooting and thus could concentrate on improving the model instead of trying to fix errors, something LLAMA lacked if you look at the first video.
Below is GPT-4 Turbo doing its thing, building an AI model to try and generate the best F1 score it can. The video is sped up as the inference time using the OpenAI API is much slower than that of GROQ. The blue text represents the input prompt from my script, and the green text is what is being returned. Red would be errors, and purple would be the results of the model after being run. On the left is the generated code. You will see it being updated with each loop. On the right are the “logs” from the script.
There were many times when I either had to stop the script because the LLM went into a loop and tried to fix the same issue over and over. Implementing some sort of memory management would most likely have helped with this, but that would have been another headache and was not really part of this POC. Other times, I had to manually install packages that were needed to train the model. I could have told the LLM to add this to the code that was being executed, but even with the “security agent,” I did not want the LLM to install random Python packages. Especially since I did not take the time to run this in a separate environment. However, I suppose that would have been another “wow” moment to see the LLM not only generate code but also maintain the Python packages it needed as well.
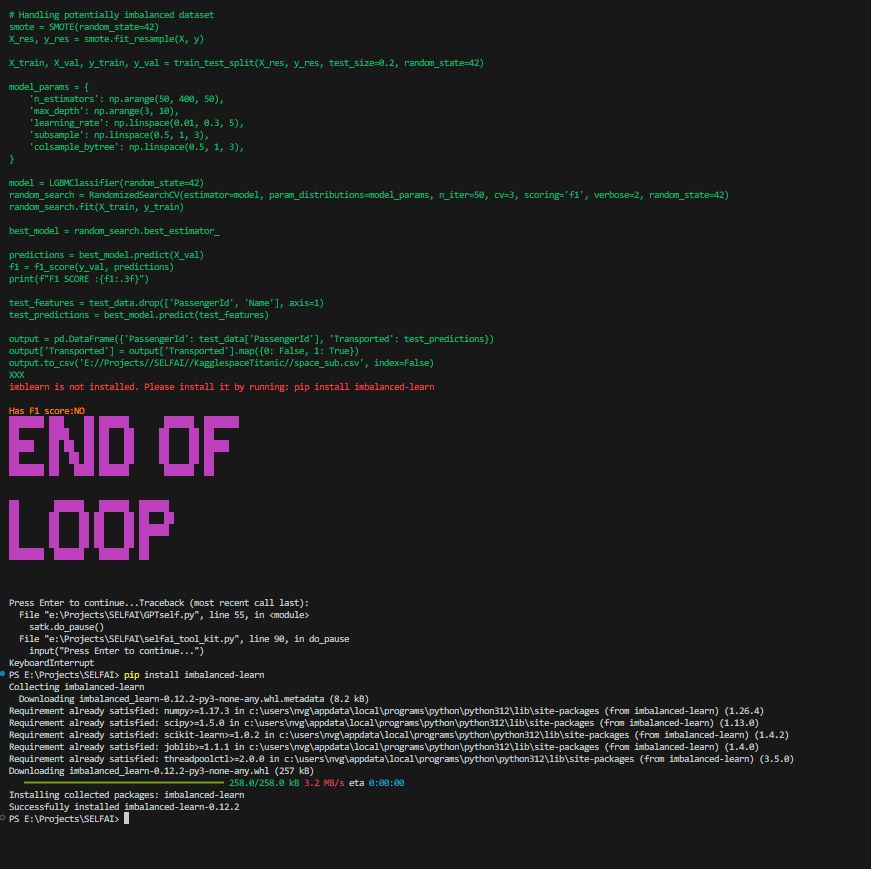
Since watching the video to see the code might not give you the full picture of how many times the code is being updated, below is a short snippet of just the code changes. Sometimes it’s one line being changed, other times most, if not all, of the code is being updated depending on the error or enhancement needed. This is still kind of mind-blowing that all these updates and changes are being made with no human intervention!
Since GPT-Omni was recently released, I just had to test it as well. With the couple of runs I did with GPT-O, I must say it managed rather well, whether it was with code generation, data wrangling, or just plain “big picture” logic. Below is GPT-O doing its thing. It managed very well for a long time, each time improving on the previous best model—well, most of the time. There were still errors and bugs, but it fixed them rather quickly. The recording below is one of those cases where it got stuck in a “loop” trying to fix the same error over and over.
Overall, I would say this POC was a great success. I’m sure it would have been even easier using official agent software, but it was nice to have full control over what I sent and got back from the LLM. And this was just one use case. I set up the structure in such a way that one would simply need to change the initial input prompts to get the LLM to build something else. Even another LLM… (evil laugh). Perhaps a self-improving novel where the writing of the novel got better and better. Or generating a 3D model of a motor, making the car more and more streamlined with every pass. Perhaps even building a model that gets better and better at playing the stock market… you never know?
And if you were wondering how well this self-improving AI did on the Kaggle scoreboard, as of the time of me writing this, I’m currently at #369 out of 2646 teams.

Until I build something that I can sell commercially feel free to have a look at the code on my GitHub account for those who wish to try this out for themselves.
